Abstract
3D semantic occupancy prediction networks have demonstrated remarkable capabilities in reconstructing the geometric and semantic structure of 3D scenes, providing crucial information for robot navigation and autonomous driving systems. However, due to their large overhead from dense network structure designs, existing networks face challenges balancing accuracy and latency. In this paper, we introduce OccRWKV, an efficient semantic occupancy network inspired by Receptance Weighted Key Value (RWKV).
OccRWKV separates semantics, occupancy prediction, and feature fusion into distinct branches, each incorporating Sem-RWKV and Geo-RWKV blocks. These blocks are designed to capture long-range dependencies, enabling the network to learn domain-specific representation (i.e., semantics and geometry), which enhances prediction accuracy. Leveraging the sparse nature of real-world 3D occupancy, we reduce computational overhead by projecting features into the bird's-eye view (BEV) space and propose a BEV-RWKV block for efficient feature enhancement and fusion. This enables real-time inference at 22.2 FPS without compromising performance.
Experiments demonstrate that OccRWKV outperforms the state-of-the-art methods on the SemanticKITTI dataset, achieving a mIoU of 25.1 while being 20 times faster than the best baseline, Co-Occ, making it suitable for real-time deployment on robots to enhance autonomous navigation efficiency. To support the community and ensure reproducibility, we will release the code for reference.
OccRWKV Key Components
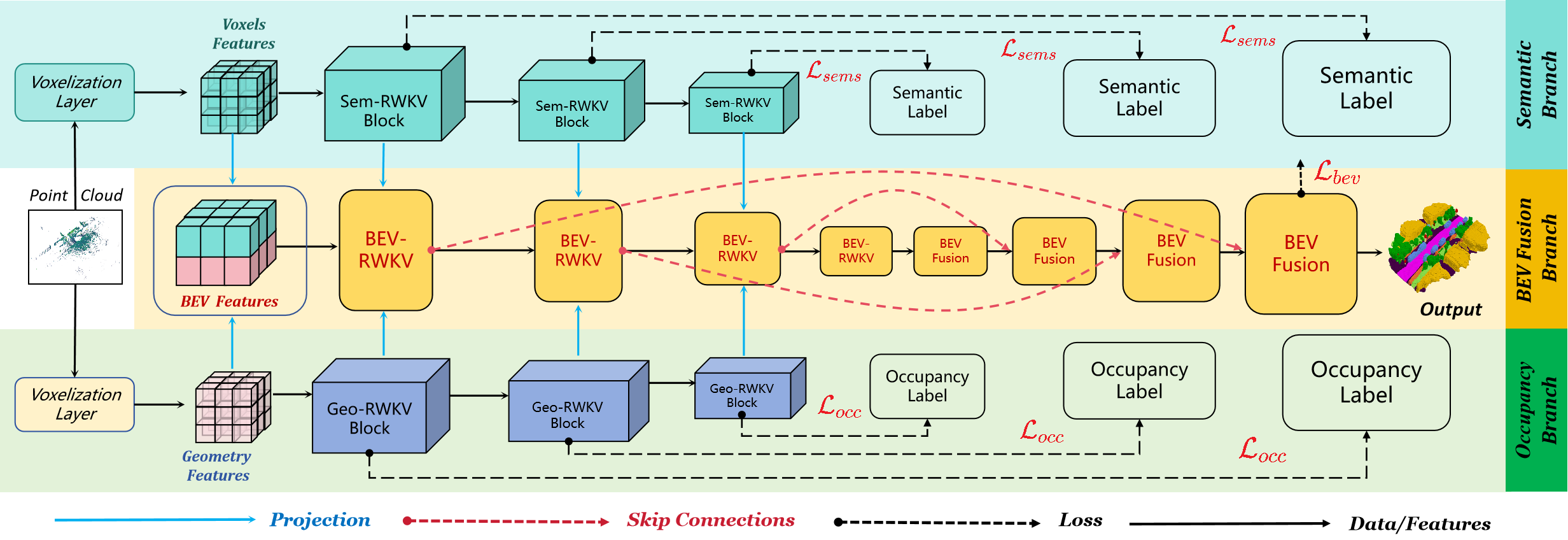
OccRWKV Overview
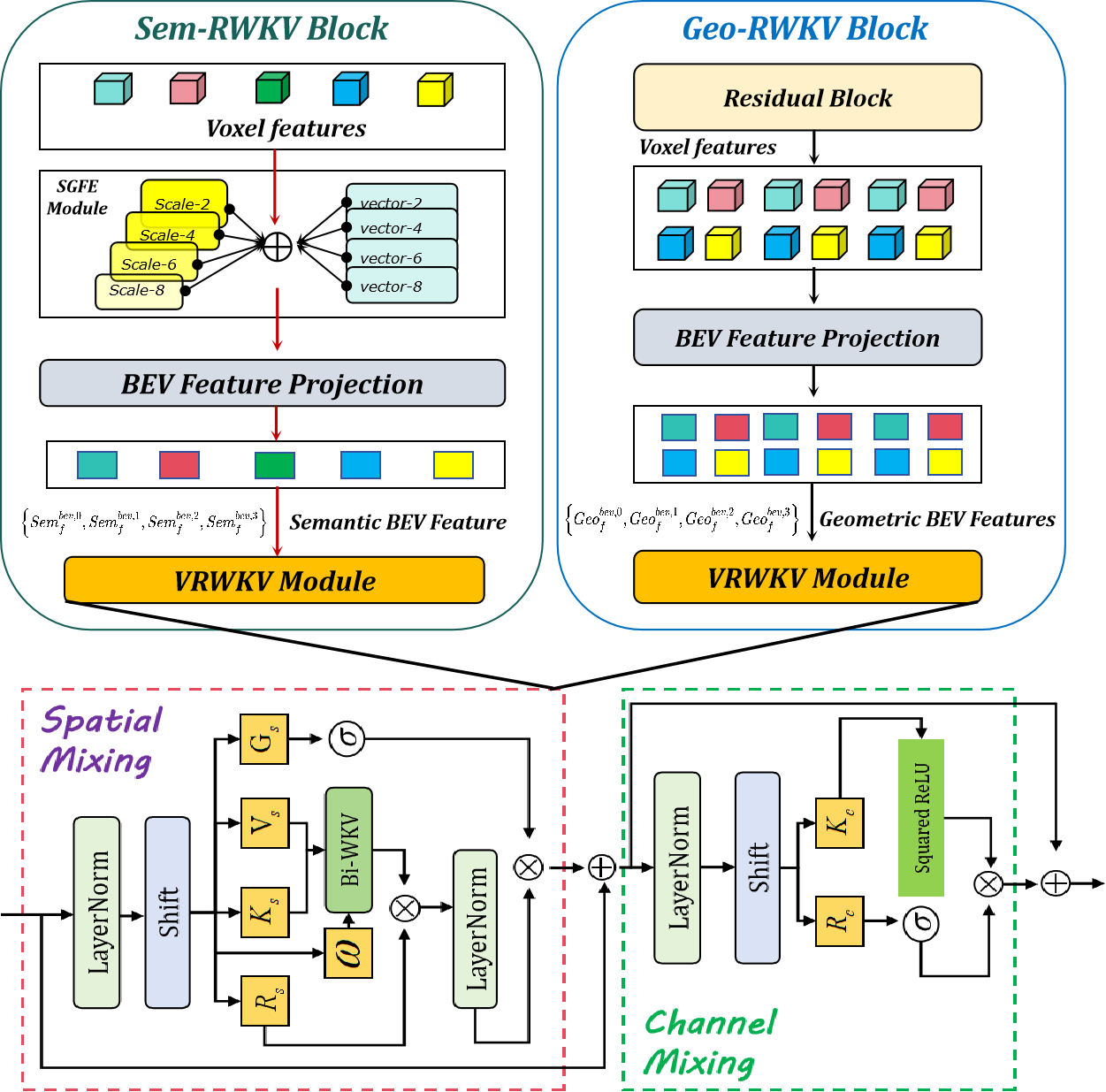
Sem-RWKV Block and Geo-RWKV Block
Experiments
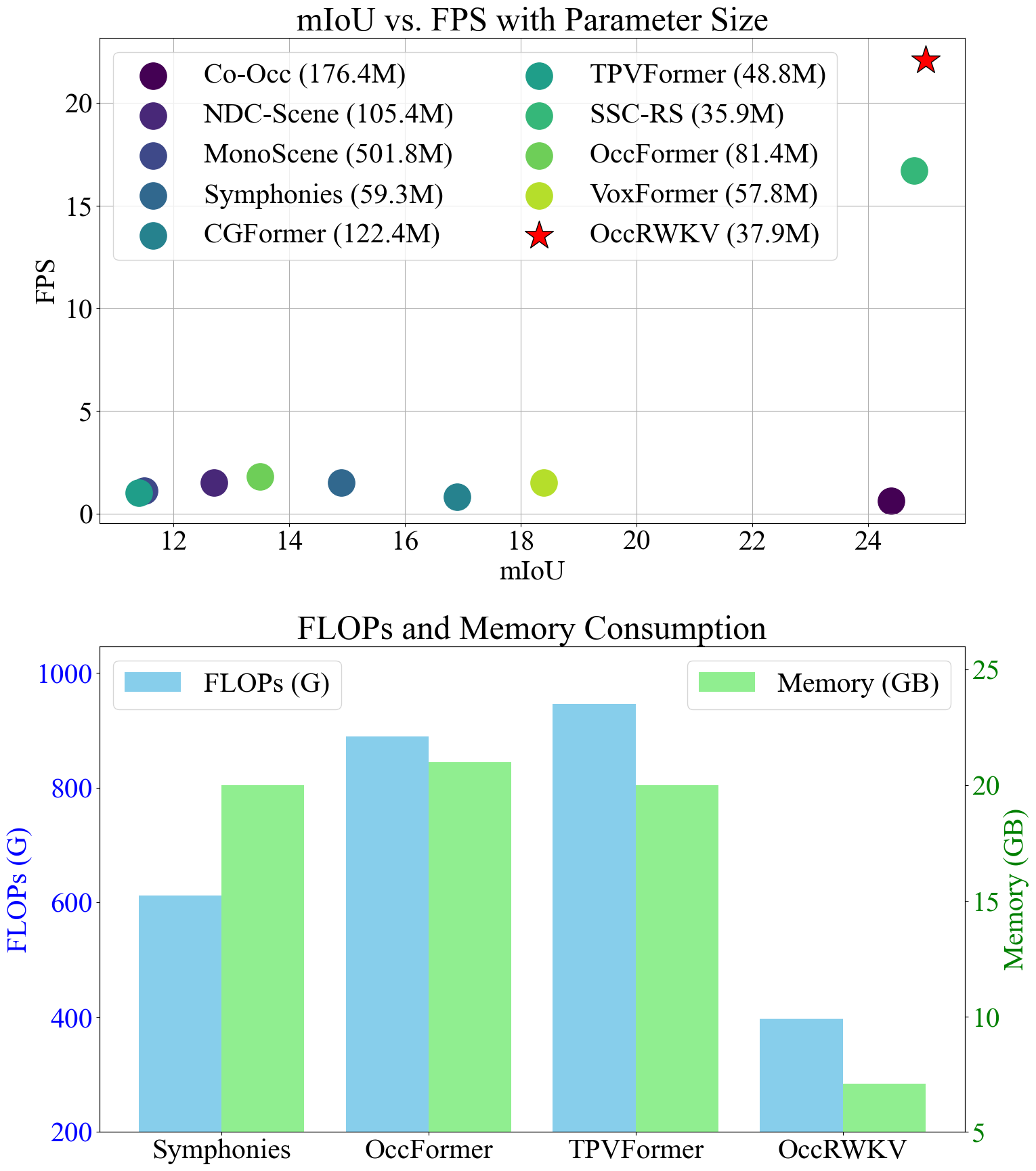
Performance and Efficiency of OccRWKV
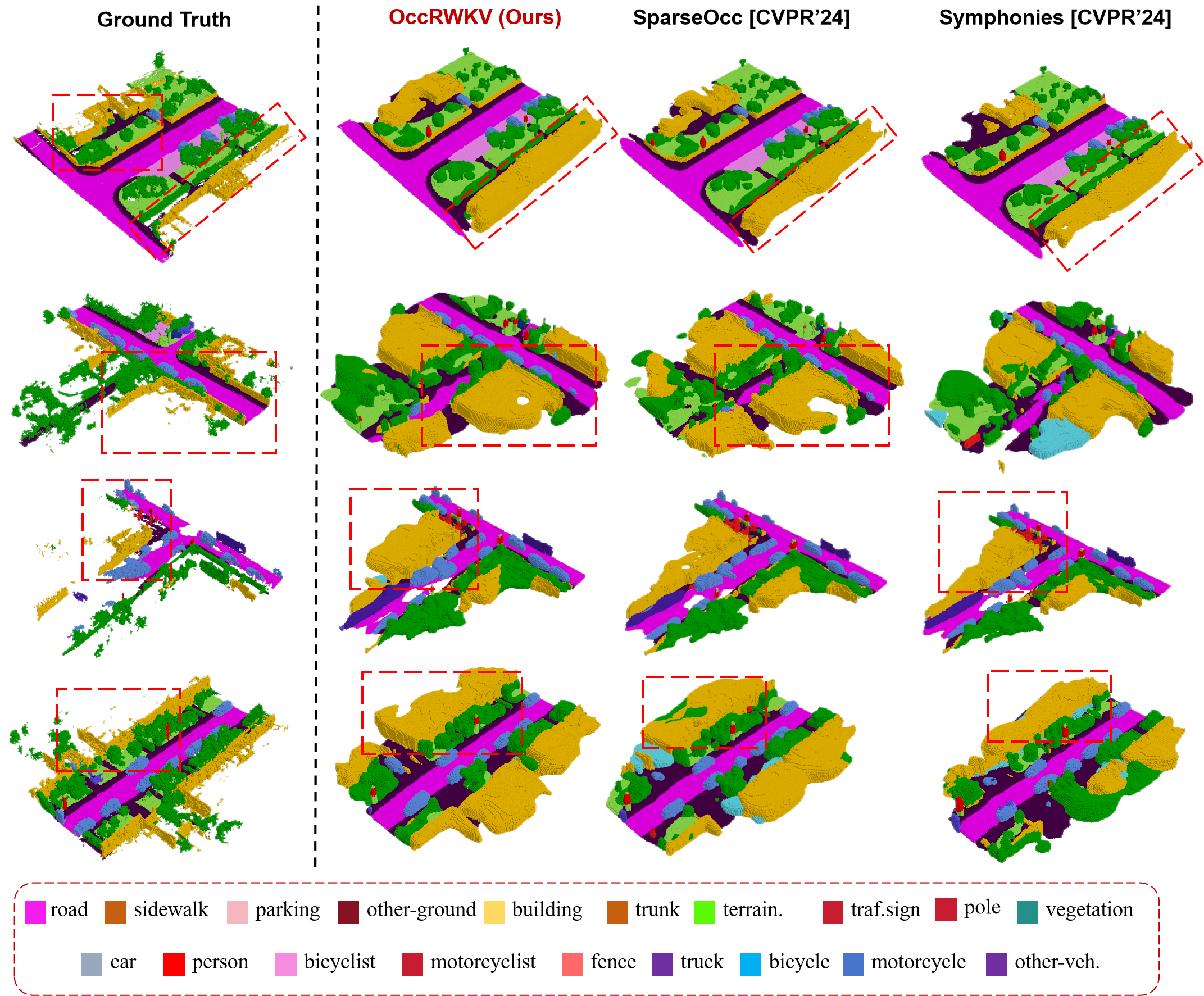
OccRWKV Prediction Results

Qualitative Results of Ablation Experiments
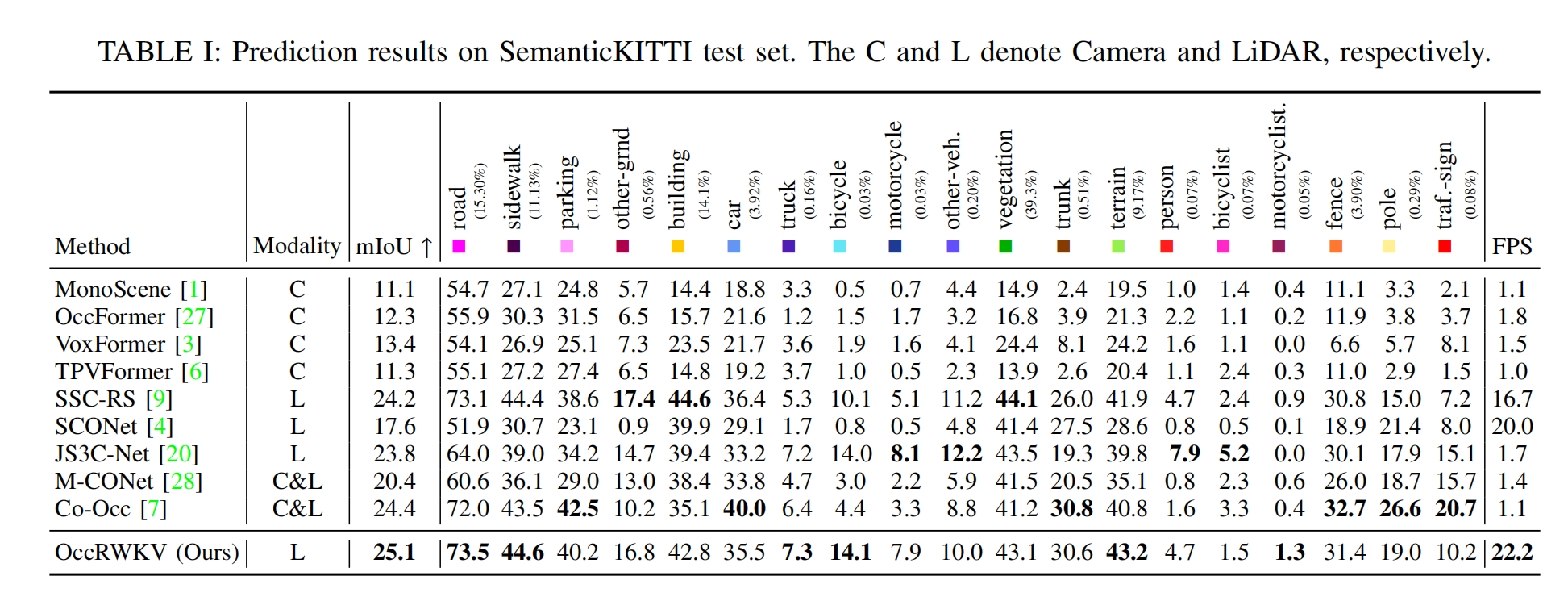
Performance comparison on the SemanticKITTI test set
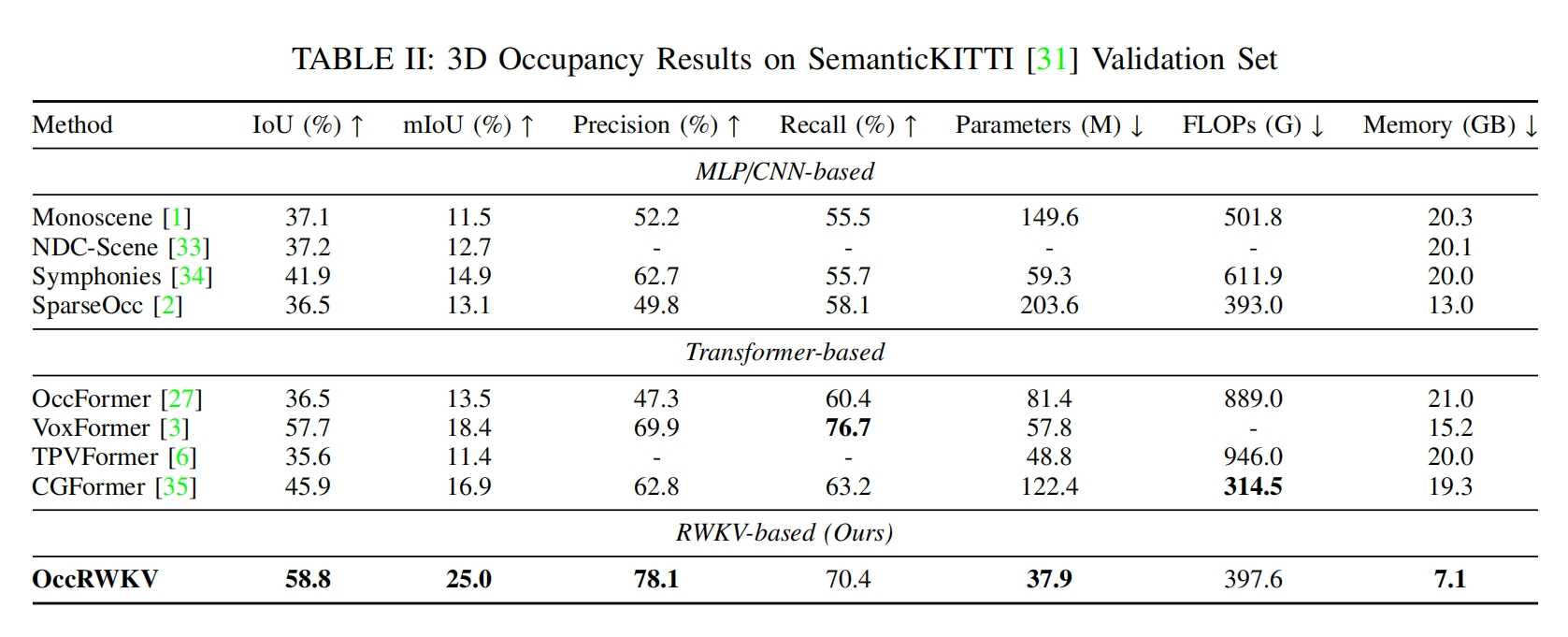
Efficiency comparison on the SemanticKITTI test set
BibTeX
@article{wang2024occrwkv,
title={OccRWKV: Rethinking Efficient 3D Semantic Occupancy Prediction with Linear Complexity},
author={Wang, Junming and Yin, Wei and Long, Xiaoxiao and Zhang, Xinyu and Xing, Zebing and Guo, Xiaoyang and Qian, Zhang},
year={2024}
}